Video Analysis of Skill and Technique (VAST)
Supervisor: Jia Deng | Co-author: Yu-Wei Chao, Xieyang Liu
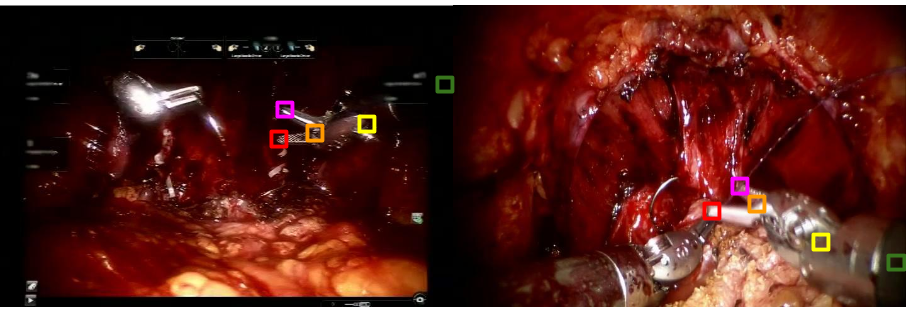
Goal
A surgeon's technical skill may be a pivotal determinant of patient outcomes. Because robotic surgery can be recorded, computer vision analysis may have unique advantages for skill assessment that is objective, efficient and scalable. The goal of this project is to evaluate technical skill of surgeon based on robotic prostatectomy videos. Typical scenes of robotic prostatectomy can be found in the figure above.
Method
The goal is approached in three steps.
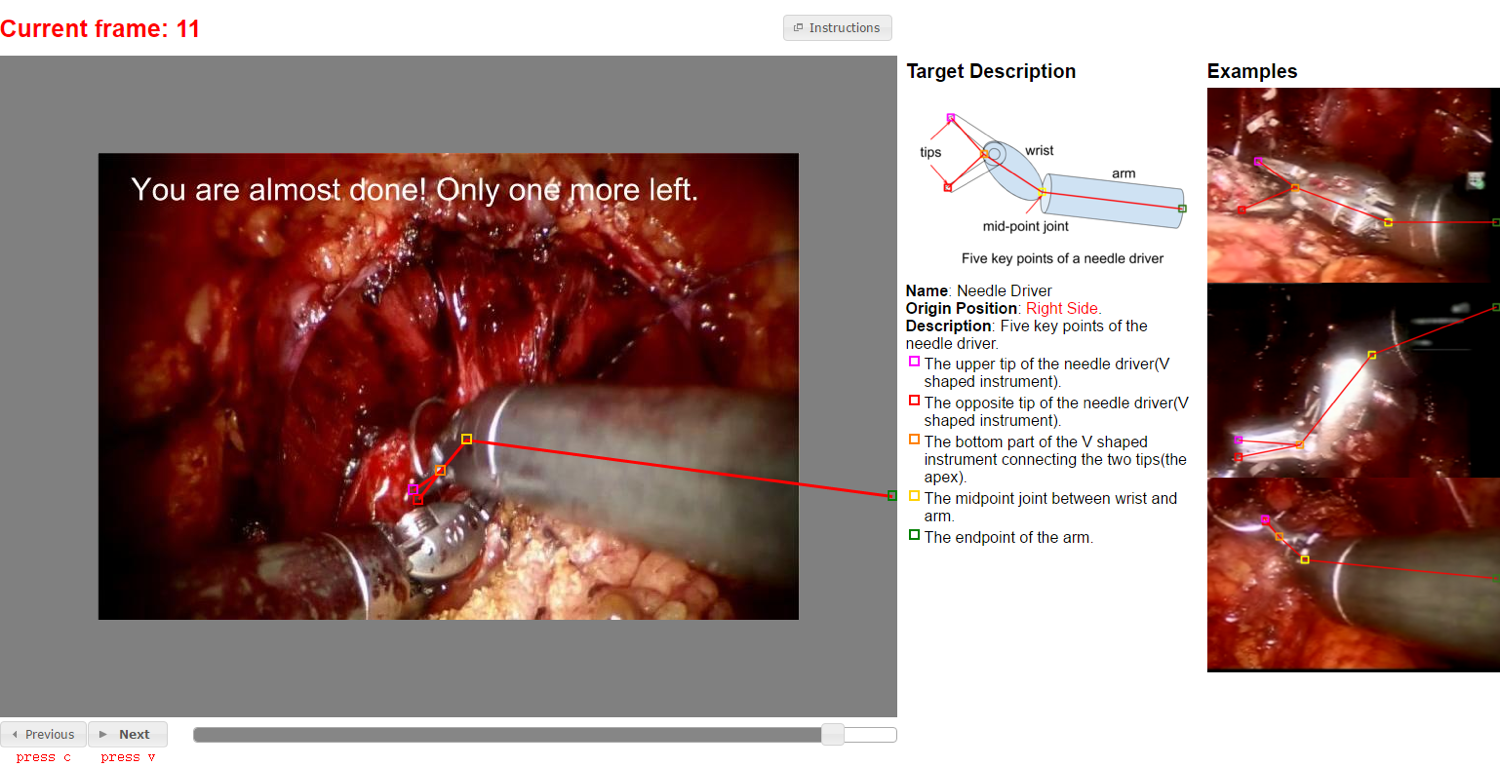
Using Amazon Mechanic Turk (MTurk) crowd-source platform to annotate robotic surgery videos (5 parts of the robotic instrument) for vision-analysis.
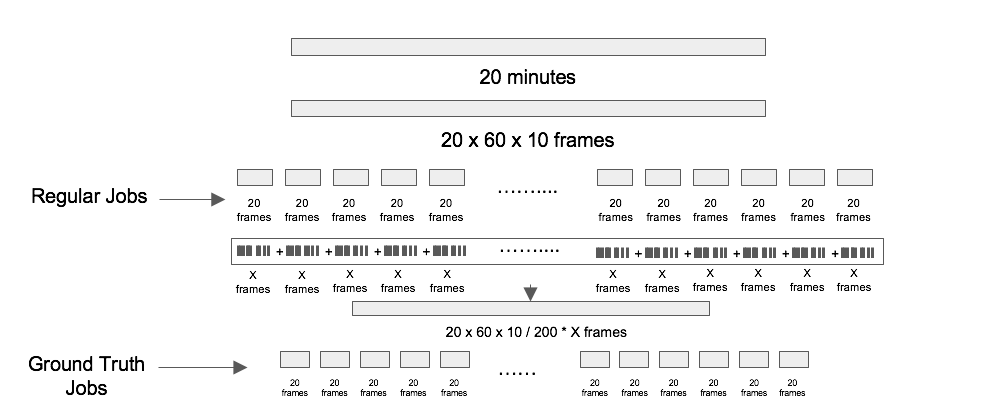
Our quality control strategy is to sample 3 out of every 20 frames and have multiple workers annotate them. The sample frames are named 'GT frames' and other ordinary frames are named 'Regular frames'. We take the average of annotations on each GT frame and consider them as GT annotations for each GT frame. After that, we use the GT annotations to measure the quality of the annotations of the 20 frames where the GT frames are sampled. Experiments are conducted to select optimal parameters minimizing average annotation error.
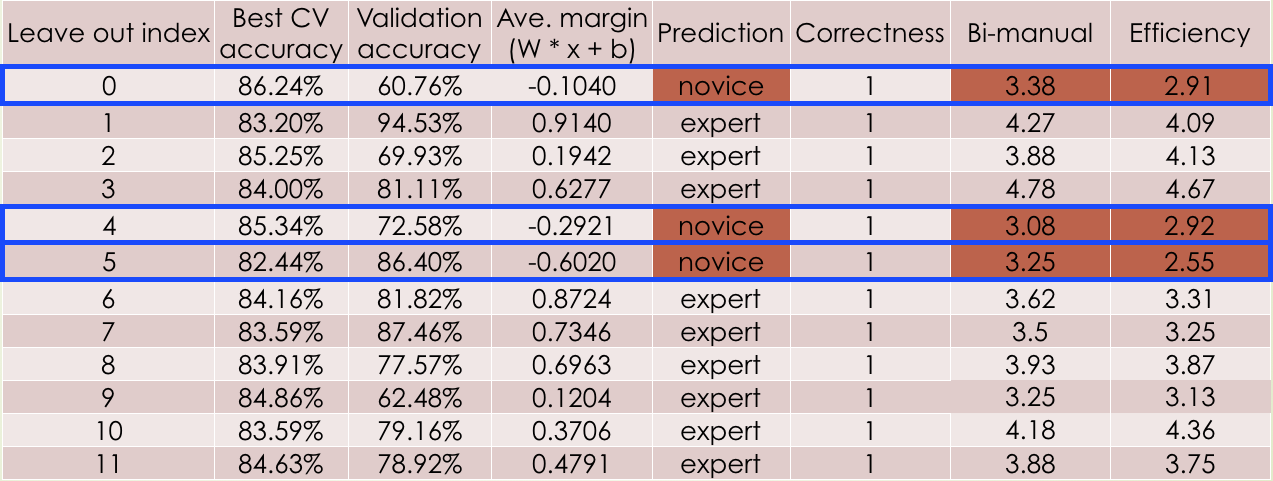
Based on the crowd-source annotation data, we proposed a system to label the technical skill presented by the surgery video as 'novice' or 'professional'. Using these videos we trained a linear support vector machine (SVM), and sampled consecutive frames to study VAST metrics for instruments including velocity, trajectory, smoothness of movements, and relationship to contralateral instrument. We applied the SVM to learn and classify each video into high or low skill. To evaluate performance we used 11 videos as training data and tested on the remaining 1 video, repeating the experiment 12 times and averaged the accuracy.
We achieved 100% classification accuracy making use of annotations from both left and right robotic arms. Investigation on Global evaluative assessment of robotic skills (GEARS) shows that 'Bi-manual' and 'Efficiency' are two metrics that give highest variation among all the videos, thus the input feature vectors of SVM are constructed mainly based on these two metrics.
Our Ultimate goal is to build a autonomous surgical skill evaluation system. Therefore, the last step is to propose an algorithm to automatically annotate video frames. We make use of stacked Hourglass model to recognize robotic arm pose in every frame and in this way we could obtain annotation of desired joints of robotic arms. We are still working on fine-tuning the network, stay tunned!
We obtained large scale annotations of surgical videos of robotic prostatectomy from surgeons in the Michigan Urological Surgery Improvement Collaborative (MUSIC) to serve as training and testing data. We developed a novel user interface for data acquisition and enforced quality control mechanism to ensure high annotation accuracy. So far, 146,309 video frames were annotated by 925 crowdworkers and we are still working on collecting more data.
Last updated on 2016/12/25